Cái này có trong cuốn đề thi quốc gia. Bạn ra hiệu sách chắc là có đấy.
Cái này chứng minh khà đơn giản. Hoặc bạn đọc bài này sẽ hiểu được nhiều đấy.
Nguồn gốc, quá trình tiến hóa của DNA và hệ thống nhân đôi DNA
22/10/2006
Sự chuyển tiếp từ thế giới của RNA sang thế giới của DNA là một sự kiện lớn trong lịch sử của sự sống. Sự xuất hiện của DNA đòi hỏi sự xuất hiện các hoạt động của các enzyme đối với quá trình tổng hợp các tiền chất của DNA, phiên mã ngược các khuôn RNA và nhân đôi các phân tử DNA sợi đơn hoặc sợi đôi. Các số liệu gần đây từ các lĩnh vực So sánh Hệ gene, Sinh học cấu trúc và Hóa Sinh đã cho thấy rằng rất nhiều các hoạt động enzyme này đã được tạo ra không chỉ một lần. Điều này chỉ ra rằng sự chuyển tiếp từ hệ gene RNA sang DNA phức tạp hơn người ta nghĩ trước đây.
Sự phân bố các họ protein khác nhau tương ứng với các hoạt động này ở ba lãnh giới của sự sống (Archaea, Eukarya và Bacteria) khá là khó hiểu. Trong nhiều trường hợp, Archaea và Eukarya có cùng một phiên bản của các protein này trong khi Bacteria lại có một phiên bản khác. Tuy nhiên trong những trường hợp khác, ví dụ thymidylate synthases hoặc DNA topoisomerase type II, sự phân bố theo cây phả hệ của các protein này không tuân theo một mô hình đơn giản. Nhiều giả thuyết đã được đề xuất để giải thích những quan sát này, như sự xuất hiện độc lập của DNA và các protein tham gia nhân đôi DNA, sự chuyển các gene cổ và mất gene hoặc sự thay thế theo phương thức không tương đồng giữa các loài. Chúng ta sẽ đánh giá tất cả các giả thuyết đó trong bài này với việc nhấn mạnh hơn về các đề xuất rằng virus đã đóng một vai trò quan trọng trong nguồn gốc và sự tiến hóa của các protein tham gia nhân đôi DNA và có khả năng chính cả bản thân DNA.
Giới thiệu
Mọi sinh vật cấu tạo từ tế bào đều có hệ gene DNA sợi kép vì vậy nguồn gốc DNA và cơ chế nhân đôi của DNA là một vấn đề quan trọng trong sự hiểu biểu của chúng ta về sự tiến hóa của sự sống xa xưa. Đã có lúc nhiều nhà Sinh học phân tử tin rằng sự sống mặc nhiên bắt đầu bằng sự xuất hiện trước tiên của DNA. Watson và Crick thậm chí đề xuất rằng DNA có thể nhân đôi mà không cần protein, và tự hỏi "liệu có cần một enzyme đặc biệt để tiến hành phản ứng polymer hóa hay chuỗi xoắn đơn có thể hoạt động như một enzyme". Những quan niệm cực đoan như vậy phù hợp với ý kiến cho rằng DNA là một tinh thể không có tính trật tự mà Schroedinger đã dự đoán trong cuốn sách có nhiều ảnh hưởng, "Sự sống là gì" của ông. Tình thế đã thay đổi, và các kết quả thực nghiệm qua nhiều thập kỷ đã thuyết phục chúng ta rằng quá trình tổng hợp và nhân đôi DNA thực tế đòi hỏi rất nhiều protein. Chúng ta có thể chắc chắn rằng DNA và cơ chế tổng hợp DNA xuất hiện sau trong lịch sử sự sống xa xưa, và DNA có nguồn gốc từ RNA trong một thế giới của RNA và protein. Vì vậy nguồn gốc và sự tiến hóa của các cơ chế nhân đôi DNA xảy ra ở một thời kỳ trọng yếu của tiến hóa sự sống, trải từ giai đoạn sau của thế giới RNA và sự xuất hiện của Tổ Tiên Chung Cuối Cùng (LUCA-Last Universal Cellular Ancestor) cho đến ba lãnh giới của sự sống ngày nay. Đây là lúc chúng ta có thể hào hứng tìm hiểu chi tiết về các cơ chế trổng hợp tiền chất của DNA và sự nhân đổi DNA thông qua So sánh Hệ gene và Sinh học Phân tử để lần theo lịch sử của chúng.
Sự tiến hóa của các cơ chế đặc thù liên quan đến sự nhân đôi của DNA: Hai nghiên cứu điển hình.
Sự hiểu biết thêm của chúng ta về nguồn gốc và sự tiến hóa của DNA và bộ máy nhân đôi DNA chắc chắn sẽ thu được nhiều ích lợi từ việc giải trình tự các hệ gene mới, đặc biệt là từ protist và virus. Tuy nhiên việc đào sâu hiểu biết của chúng ta về "lô gic mang tính lịch sử" ẩn trong nhiều mặt khác nhau của chính quá trình nhân đôi cũng rất quan trọng. Điều này đòi hỏi nhiều số liệu thực nghiệm hơn trên một số lượng các sinh vật lớn hơn để có được những tri thức mới từ sinh học phân tử so sánh. Chúng ta sẽ kết thúc chương này bằng việc thảo luận hai ví dụ minh họa cho nhận định này:
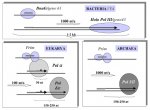
Ví dụ thứ nhất nói đến các tập hợp protein khác nhau thực hiện quá trình tổng hợp và xử lý các đoạn Okazaki ở Prokaryote và Eukaryote. Ở Pro. DNA polymerase III trực tiếp sử dụng RNA primer được tổng hợp từ DnaG (một đơn phân) để tạo ra một đoạn Okazaki đầy đủ (1000 cặp base). Một protein duy nhất, DNA Polymerase I có thể vừa phân hủy RNA primer bằng hoạt tính exonuclease 5'->3' và lấp vào chỗ trống bằng hoạt tính polymerase của nó. Cơ chế tổng hợp và xử lý các đoạn Okazaki ở Eu. dường như phức tạp hơn và ít "hợp logic", thậm chí không muốn nói là kỳ quái. Đoạn RNA primer được tổng hợp bởi Eu. primase trước hết được kéo dài trong tế bào bằng DNA polymerase α để tạo ra một primer hỗn hợp RNA-DNA (khoảng 30 cặp base) và được tổng hợp thành đoạn Okazaki đầy đủ (khoảng 100-150 cặp base) bằng DNA polymerase δ. Vai trò của DNA polymerase α khá là khó hiểu vì DNA polymerase δ có thể tổng hợp đoạn Okazaki đầy đủ chỉ từ RNA primer in vitro. Hơn nữa DNA polymerase α không có hoạt tính sửa Nu 3'->5' exonuclease cần thiết cho việc copy DNA một cách chính xác. Vì vậy quá trình xử lý đoạn Okazaki ở Eu. đòi hỏi đoạn RNA primer và cả đoạn DNA có khả năng chứa lỗi do DNA polymerase α tổng hợp phải bị loại bỏ. Quá trình này liên quan đến hoạt động kế tiếp nhau của ba protein: RPA, Dna2 và FEN-1. DNA polymerase δ trước tiên sẽ thế chỗ đoạn RNA primer và đoạn DNA do DNA polymerase α tổng hợp. Chuỗi DNA đơn sau đó sẽ được bao bọc bởi RPA, có chức năng vừa ức chế quá trình thế chỗ của DNA polymerase δ tiếp tục vừa kích thích hoạt động của protein Dna2. Chuỗi Nu bị thế chỗ sau đó có thể bị cắt bởi hoạt tính endonuclease của Dna2, chừa lại một đuôi chuỗi đơn ngắn và cuối chúng chuỗi này sẽ bị phân hủy bởi flap-endonuclease FEN-1. (Hình 7)
Điều thú vị là RPA, Dna2 và FEN-1 được bảo tồn ở Archaea mặc dù thiếu vắng gene tương đồng DNA polymerase α trong hệ gene của archaea. Trong quan điểm truyền thống của tiến hóa (từ pro. đơn giản đến eu. phức tạp), hệ thống nhân đôi của Eu. là một phiên bản cỉa tiến của hệ thống của archaea. Ý nghĩa của điều này là gì? Sự cải tiến nào đã thu được từ việc có thêm sự hiện diện của một DNA polymerase không có khả năng sửa lỗi trong hệ thống? Có hay không khả năng là chính hệ thống nhân đôi của archaea thực tế có nguồn gốc từ Eu, và cơ chế xử lý đoạn Okazaki ở Archaea là di tích của một thời khi Pol α vẫn còn hiện diện? Để trả lời câu hỏi này chúng ta cần biết nhiều hơn về vai trò của Pol α và các nhân tố hoạt động khác ở bộ máy nhân đôi của Eu .và Archaea. Nói chung hệ thống nhân đôi DNA của Archaea không chỉ là phiên bản đơn giản của hệ thống Eu. (với ít các protein thực hiện cũng chức năng đó) nhưng cũng là một hệ thống hiệu quả hơn. Ví dụ tốc độ polymer hóa ở Archaea và Pro. là như nhau mặc dù kích thước chuỗi Okazaki là như nhau ở Archaea và Eu. (ngắn hơn nhiều so với ở Pro.)
Hình 7: Tổng hợp đoạn Okazaki ở ba lãnh giới và ở T4. Ở vi khuẩn và ở T4 chuỗi Okazaki được tổng hợp nhanh và có chiều dài lớn bởi một DNA polymerase duy nhất, sử dụng RNA primer. Ở Eu. đoạn Okazaki được tổng hợp chậm và có chiều dài ngắn lần lượt bởi primase 2 tiểu phần, một DNA pol. không có khả năng đọc lỗi và một DNA Pol. δ/ ε. RNA primer là đường gạch đậm, mũi tên đậm ám chỉ đoạn DNA được tổng hợp bởi Pol. alpha. Các lỗi giả định quy cho Pol. α được chỉ định bằng các dấu sao. Ở Archaea, phân tích trên máy tính gợi ý rằng một primase giống như ở Eu. tổng hợp RNA primer và chuỗi DNA được kéo dài bằng DNA Pol thuộc họ B (hoặc họ D). Các bằng chứng thực nghiệm nói lên rằng tốc độ tổng hợp DNA ở Archea khá nhanh trong khi chiều dài đoạn Okazaki là như nhau ở Archaea và Eukarya.
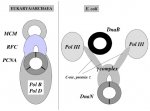
Câu chuyện thứ hai nói về cấu trúc của protein đeo kẹp ở Pro. Chúng ta đã thấy rằng, mặc dù protein kẹp và protein đeo kẹp là các protein tương đồng ở ba lãnh giới, chúng tương tác với các protein nhân đôi không tương đồng ở một phía ở Pro nhưng lại ở phía khác ở Archaea/Eukarya (đặc biệt là với DNA polymerase ở các họ khác nhau). Ở E. Coli protein tải kẹp chứa các tiểu đơn vị gọi là t, γ, δ, δ', đều là protein tương đồng với protein RFC ở Archaea/Eukarya. Cùng gene này (dnaX) mã hóa cho tiểu đơn vị γ và t. Protein t (71 kDa) là một protein đầy đủ, trái lại γ là một bản cắt ngắn (47 kDa) do chuyển dịch khung dịch mã kèm theo một mã kết thúc. Amino acid đầu C của phần dài hơn (24 kDa) ở t đã được thêm vào protein tải kẹp trong quá trình tiến hóa của Pro vì nó không có bản tương đồng ở archaea/eu. RFC protein. Phần dài hơn này cho phép protein tải kẹp đôi nối tải kẹp với helicase (DnaB) và hai Pol III. Lý do của điều này là gì? Ta có thể biện luận rằng điều này giúp tạo cấu trúc replisome của Pro., hoặc nó bổ sung cho sự thiếu vằng của một trong hai enzyme tổng hợp DNA (PolC) có ở các vi khuẩn khác (ví dụ Bacillus subtilis). Mặt khác, trong giả thuyết về sự thay thế các protein cổ tham gia quá trình nhân đôi bởi DnaB và Pol III, ta có thể hình dung phần dài hơn ở đuôi C là một mẹo mà các protein này tìm ra để buộc tải kẹp phải tương tác với chúng thay vì tương tác với các protein trong hệ thống nhân đôi cổ (gần giống như protein P của bacteriophage γ buộc protein ức chế DnaA phải tương tác với nó thay vì với DnaC). Tuy nhiên tình huống này bị đối chọi bởi sự phân bố có giới hạn của phần dài hơn đầu C ở lãnh giới vi khuẩn. Rõ ràng chúng ta muốn biết nhiều hơn về các phức replisome hiện diện ở vi khuẩn và để hiểu chúng liên quan về mặt tiến hóa như thế nào để tìm ra ý nghĩa của một gene khó hiểu như gene dnaX. (Hình 9)
Hình 9: Tương tác giữa các kẹp và tải kẹp với các phần không tương đồng của replisome ở Archaea/Eukarya và ở E.coli. Ở Eukarya và Archaea, RFC và PCNA (protein tương tự tương ứng của phức γ vi khuẩn và DnaN) tương tác với helciase (MCM) và Pol. thuộc họ B hoặc D. Ở E.coli phức kép γ tương tác với heclicase DnaB và 2 Pol III thông qua chuỗi polypeptide kéo dài ở đầu C của protein t, hai protein không phải là những protein tương đồng với các protein tương ứng về chức năng ở Archea và Eukarya. Không phải tất cả vi khuẩn đều có đoạn kéo dài ở đầu C
Chú thích:
- Clamp loader is a 5 subunit protein complex which is responsible for loading the β clamp on to DNA at the replication fork
- Replication factor C (RFC) is a five subunit DNA polymerase (Pol) delta/straightepsilon accessory factor required at the replication fork for loading the essential processivity factor PCNA onto the 3'-ends of nascent DNA strands.
This site uses cookies to help personalise content, tailor your experience and to keep you logged in if you register.
By continuing to use this site, you are consenting to our use of cookies.